Manage Multi-Node Clusters with Embedded Cluster
This topic describes managing nodes in clusters created with Replicated Embedded Cluster, including how to add nodes and enable high-availability for multi-node clusters.
Limitations
Multi-node clusters with Embedded Cluster have the following limitations:
-
Support for multi-node clusters with Embedded Cluster is Beta. Only single-node embedded clusters are Generally Available (GA).
-
High availability for Embedded Cluster in an Alpha feature. This feature is subject to change, including breaking changes. For more information about this feature, reach out to Alex Parker at alexp@replicated.com.
-
The same Embedded Cluster data directory used at installation is used for all nodes joined to the cluster. This is either the default
/var/lib/embedded-clusterdirectory or the directory set with the--data-dirflag. You cannot choose a different data directory for Embedded Cluster when joining nodes. -
More than one controller node should not be joined at the same time. When joining a controller node, a warning is printed that explains that the user should not attempt to join another node until the controller node joins successfully.
-
Setting node roles with the Embedded Cluster Config roles key is Beta.
Add Nodes to a Cluster (Beta)
You can add nodes to create a multi-node cluster in online (internet-connected) and air-gapped (limited or no outbound internet access) environments. The Admin Console provides the join command that you use to join nodes to the cluster.
Multi-node clusters are not highly available by default. For information about enabling high availability, see Enable High Availability for Multi-Node Clusters (Alpha) below.
To add nodes to a cluster:
-
(Optional) In the Embedded Cluster Config, configure the
roleskey to customize node roles. For more information, see roles in Embedded Cluster Config. When you are done, create and promote a new release with the updated Config. -
Do one of the following to get the join command from the Admin Console:
-
To add nodes during the application installation process, follow the steps in Online Installation with Embedded Cluster or Air Gap Installation with Embedded Cluster to install. A Nodes screen is displayed as part of the installation flow in the Admin Console that allows you to choose a node role and copy the relevant join command.
-
Otherwise, if you have already installed the application:
-
Log in to the Admin Console.
-
If you promoted a new release that configures the
roleskey in the Embedded Cluster Config, update the instance to the new version. See Perform Updates in Embedded Clusters. -
Go to Cluster Management > Add node at the top of the page.
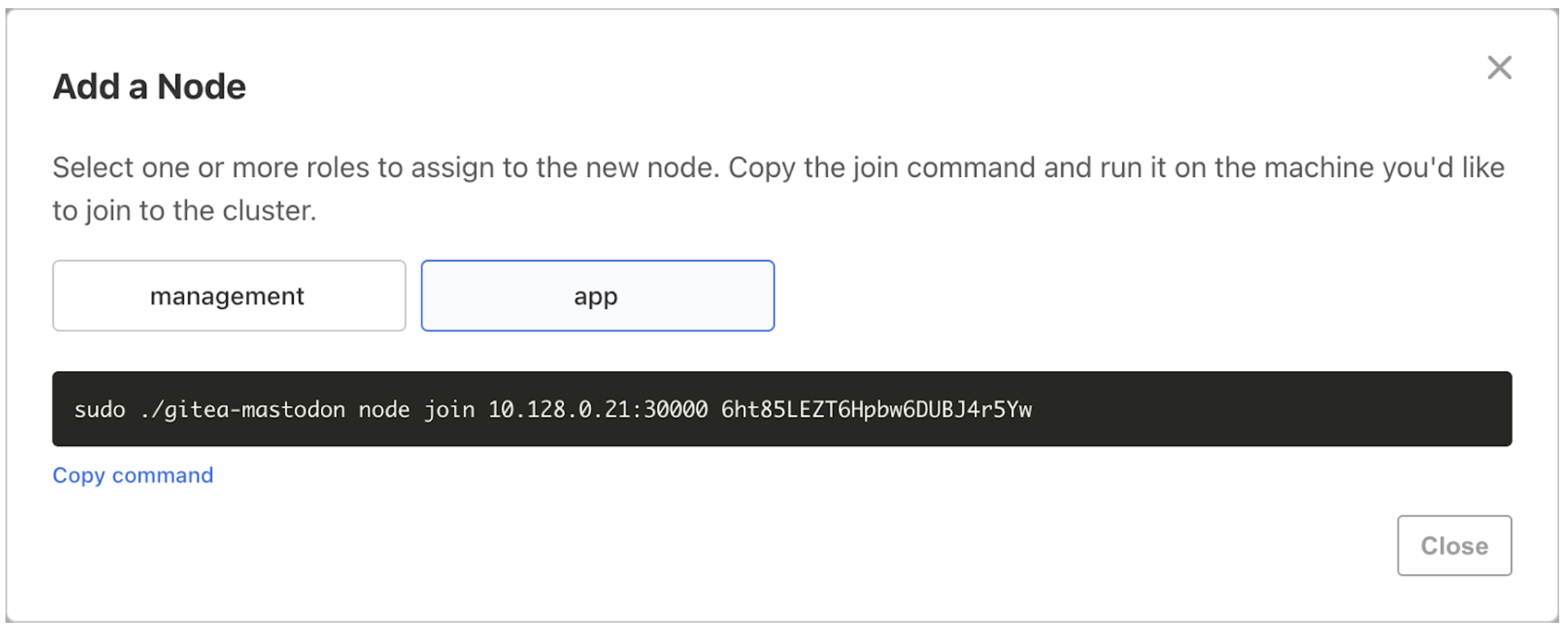
-
-
-
Either on the Admin Console Nodes screen that is displayed during installation or in the Add a Node dialog, select one or more roles for the new node that you will join. Copy the join command.
Note the following:
-
If the Embedded Cluster Config roles key is not configured, all new nodes joined to the cluster are assigned the
controllerrole by default. Thecontrollerrole designates nodes that run the Kubernetes control plane. Controller nodes can also run other workloads, such as application or Replicated KOTS workloads. -
The role cannot be changed after a node is added. If you need to change a node’s role, reset the node and add it again with the new role.
-
-
Do one of the following to make the Embedded Cluster installation assets available on the machine that you will join to the cluster:
-
For online (internet-connected) installations: SSH onto the machine that you will join. Then, use the same commands that you ran during installation to download and untar the Embedded Cluster installation assets on the machine. See Online Installation with Embedded Cluster.
-
For air gap installations with limited or no outbound internet access: On a machine that has internet access, download the Embedded Cluster installation assets (including the air gap bundle) using the same command that you ran during installation. See Air Gap Installation with Embedded Cluster. Then, move the downloaded assets to the air-gapped machine that you will join, and untar.
importantThe Embedded Cluster installation assets on each node must all be the same version. If you use a different version than what is installed elsewhere in the cluster, the cluster will not be stable. To download a specific version of the Embedded Cluster assets, select a version in the Embedded cluster install instructions dialog.
-
-
On the machine that you will join to the cluster, run the join command that you copied from the Admin Console.
Example:
sudo ./APP_SLUG join 10.128.0.32:30000 TxXboDstBAamXaPdleSK7LidAir Gap Example:
sudo ./APP_SLUG join --airgap-bundle APP_SLUG.airgap 10.128.0.32:30000 TxXboDstBAamXaPdleSK7Lid -
In the Admin Console, either on the installation Nodes screen or on the Cluster Management page, verify that the node appears. Wait for the node's status to change to Ready.
-
Repeat these steps for each node you want to add.
High Availability for Multi-Node Clusters (Alpha)
High availability for Embedded Cluster in an Alpha feature. This feature is subject to change, including breaking changes. For more information about this feature, reach out to Alex Parker at alexp@replicated.com.
Multi-node clusters are not highly available by default. The first node of the cluster holds important data for Kubernetes and KOTS, such that the loss of this node would be catastrophic for the cluster. Enabling high availability requires that at least three controller nodes are present in the cluster.
Users are automatically prompted to enable HA when joining the third controller node to a cluster. Alternatively, users can enable HA with the enable-ha command after adding three or more controller nodes.
HA Architecture
The following diagram shows the architecture of an HA multi-node Embedded Cluster installation:
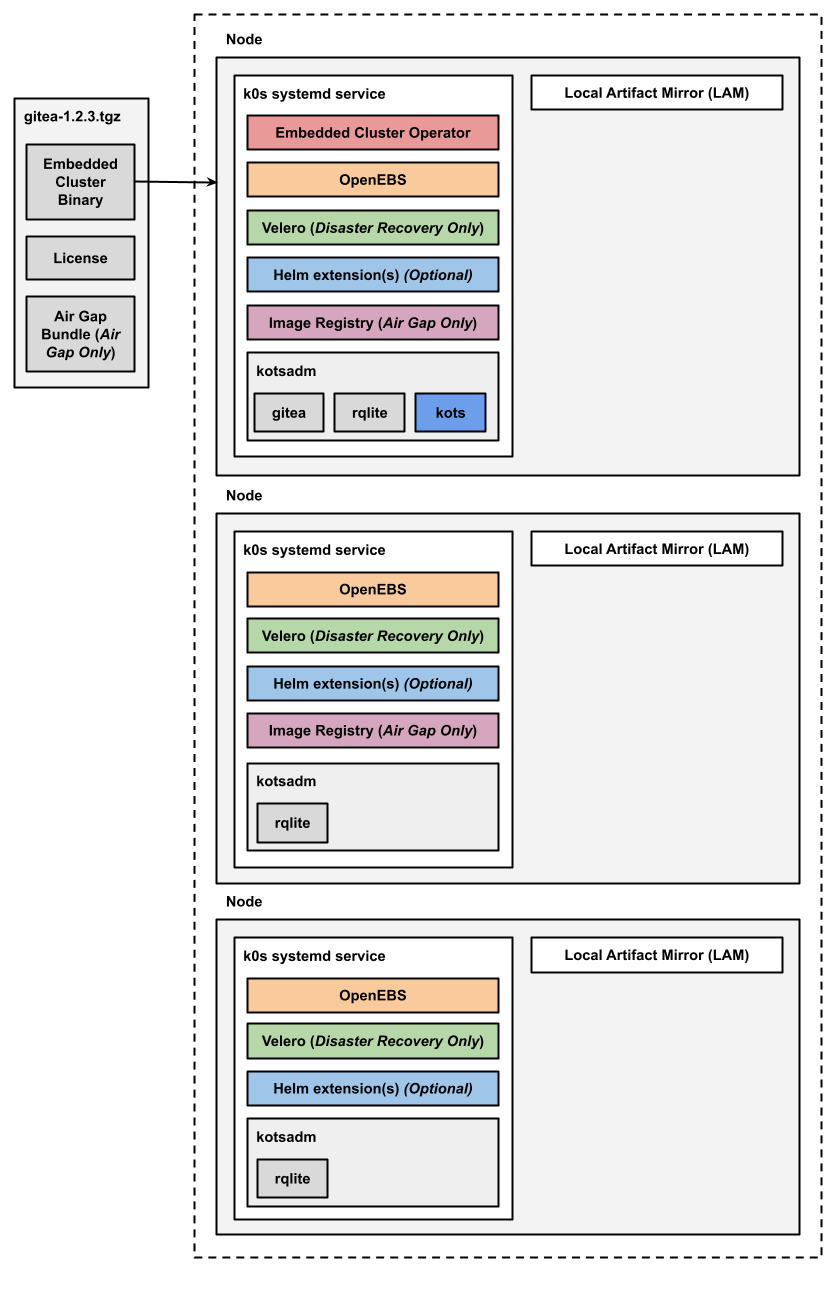
View a larger version of this image
As shown in the diagram above, in HA installations with Embedded Cluster:
- A single replica of the Embedded Cluster Operator is deployed and runs on a controller node.
- A single replica of the KOTS Admin Console is deployed and runs on a controller node.
- Three replicas of rqlite are deployed in the kotsadm namespace. Rqlite is used by KOTS to store information such as support bundles, version history, application metadata, and other small amounts of data needed to manage the application.
- For installations that include disaster recovery, the Velero pod is deployed on one node. The Velero Node Agent runs on each node in the cluster. The Node Agent is a Kubernetes DaemonSet that performs backup and restore tasks such as creating snapshots and transferring data during restores.
- For air gap installations, two replicas of the air gap image registry are deployed.
Any Helm extensions that you include in the Embedded Cluster Config are installed in the cluster depending on the given chart and whether or not it is configured to be deployed with high availability.
For more information about the Embedded Cluster built-in extensions, see Built-In Extensions in Embedded Cluster Overview.
Requirements
Enabling high availability has the following requirements:
-
High availability is supported with Embedded Cluster 1.4.1 and later.
-
The
enable-hacommand is available with Embedded Cluster 2.3.0 and later. -
High availability is supported only for clusters where at least three nodes with the
controllerrole are present.
Best Practices for High Availability
Consider the following best practices and recommendations for creating HA clusters:
-
At least three controller nodes that run the Kubernetes control plane are required for HA. This is because clusters use a quorum system, in which more than half the nodes must be up and reachable. In clusters with three controller nodes, the Kubernetes control plane can continue to operate if one node fails because a quorum can still be reached by the remaining two nodes. By default, with Embedded Cluster, all new nodes added to a cluster are controller nodes. For information about customizing the
controllernode role, see roles in Embedded Cluster Config. -
Always use an odd number of controller nodes in HA clusters. Using an odd number of controller nodes ensures that the cluster can make decisions efficiently with quorum calculations. Clusters with an odd number of controller nodes also avoid split-brain scenarios where the cluster runs as two, independent groups of nodes, resulting in inconsistencies and conflicts.
-
You can have any number of worker nodes in HA clusters. Worker nodes do not run the Kubernetes control plane, but can run workloads such as application or Replicated KOTS workloads.
Create a Multi-Node Cluster with High Availability
You can enable high availability for a multi-node cluster when joining the third controller node. Alternatively, you can enable HA for an existing cluster with three or more controller nodes. For more information, see Enable High Availability For an Existing Cluster below.
To create a multi-node HA cluster:
-
Set up a cluster with at least two controller nodes. You can do an online (internet-connected) or air gap installation. For more information, see Online Installation with Embedded Cluster or Air Gap Installation with Embedded Cluster.
-
SSH onto a third node that you want to join to the cluster as a controller.
-
On the third node, run the join command provided in the Admin Console Cluster Management tab.
Example:
sudo ./APP_SLUG join 10.128.0.80:30000 tI13KUWITdIerfdMcWTA4HpfWhere
APP_SLUGis the unique slug for the application.noteFor Embedded Cluster versions earlier than 2.3.0, pass the
--enable-haflag with thejoincommand. -
In response to the prompt asking if you want to enable high availability, type
yoryes. -
Wait for the migration to HA to complete.
Enable High Availability For an Existing Cluster
To enable high availability for an existing Embedded Cluster installation with three or more controller nodes, run the following command:
sudo ./APP_SLUG enable-ha
Where APP_SLUG is the unique slug for the application.